On-demand Resource Control for Micro-serviced Company by Autoscale
Last article describes how to quickly deploy the Company demo on K8S. This article will continue to demonstrate the benefits of micro-service architecture, use auto-scale of K8S in Company to achieve on-demand fine-grained resources.
Prepare
Prepare K8S Environment
Install monitor Heapster and Grafana in K8S to enable auto-scale ability in K8S:
Get one-click installing scripts in the author’s repo,update value of api-server as following and run kube.sh to start,
vi LinuxCon-Beijing-WorkShop/kubernetes/heapster/deploy/kube-config/influxdb/heapster.yaml
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: gcr.io/google_containers/heapster-amd64:v1.4.1
imagePullPolicy: IfNotPresent
command:
- /heapster
#use 'kubernetes' directly if installed inside the cluster
- --source=kubernetes
#use the practical api-server address if installed outside the cluster
# - --source=kubernetes:http://10.229.43.65:6443?inClusterConfig=false
- --sink=influxdb:http://monitoring-influxdb:8086
Start Company Demo
Download Company source code, restricted resources, creating auto-scaller,
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop.git
cd LinuxCon-Beijing-WorkShop/kubernetes/
bash start-autoscale.sh
In Company’s deployment script, filed of resources is added to limit 200 milli-cores to each pod(1000 milli-cores equal to 1 core),
resources:
limits:
cpu: 200m
In script start-autoscale.sh, each command create a Horizontal Pod Autoscaler that maintains between 1 and 10 replicas of the Pods controlled by its deployment created. HPA will increase and decrease the number of replicas (via the deployment) to maintain an average CPU utilization across all Pods of 50%(this means average CPU usage of 100 milli-cores),
# Create Horizontal Pod Autoscaler
kubectl autoscale deployment zipkin --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-bulletin-board --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-worker --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-doorman --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-manager --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-beekeeper --cpu-percent=50 --min=1 --max=10
HPA can be created after running start-autoscale.sh, get HPA status by the following command,
kubectl get hpa
Start Pressure Testing
export $HOST=<heapster-ip>:<heapster-port>
bash LinuxCon-Beijing-WorkShop/kubernetes/stress-test.sh
The script enable a dead loop, request to Company to calculate fibonacci number 200 times in each second, causing pressure on Company,
FIBONA_NUM=`curl -s -H "Authorization: $Authorization" -XGET "http://$HOST/worker/fibonacci/term?n=6"`
Testing Result
Following datas gets from HPA and Grafana,
 Fig 1 HPA Data of Start-up Period
Fig 1 HPA Data of Start-up Period
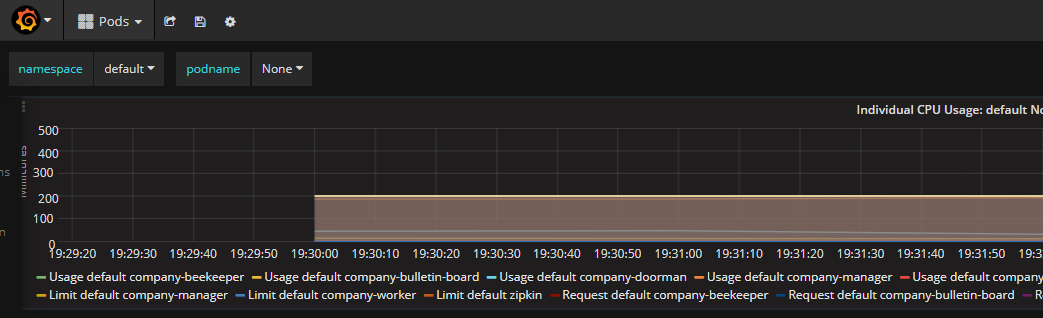 Fig 2 Granfana Data of Start-up Period
Fig 2 Granfana Data of Start-up Period
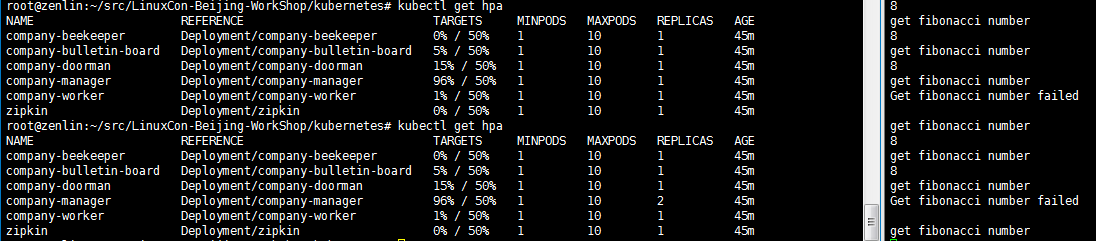 Fig 3 HPA Data of middle Period
Fig 3 HPA Data of middle Period
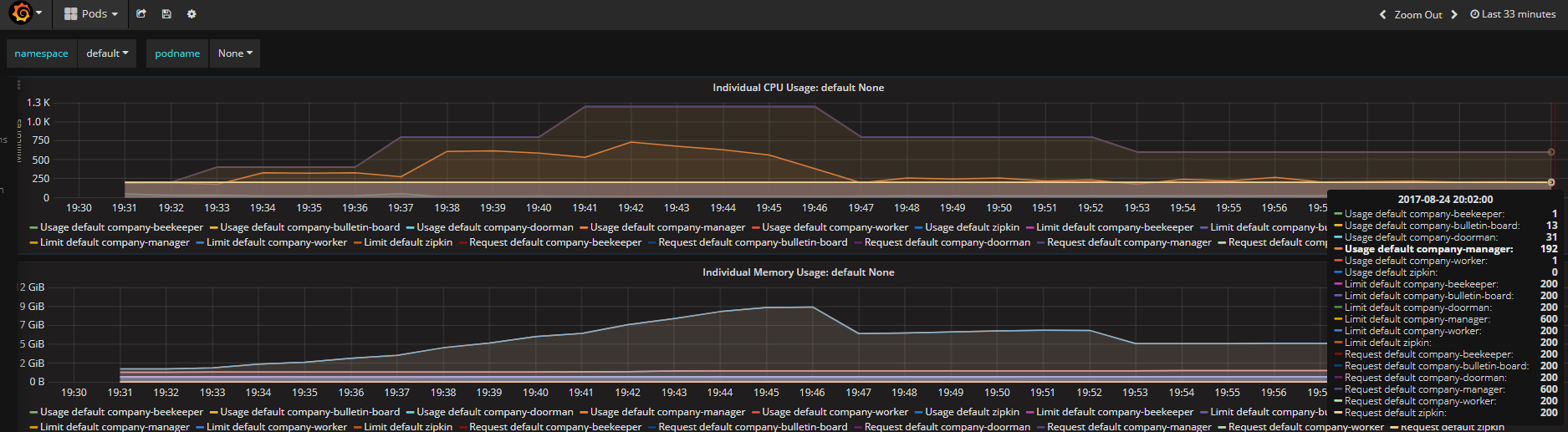 Fig 4 Granfana Data of The End
Fig 4 Granfana Data of The End
 Fig 5 HPA Data of The End
Fig 5 HPA Data of The End
Analyze the data to get the results,
-
Pressure is focused on the pod of company-manager, auto-scaler of K8S increase the pods to achieve goal, less than 50% of CPU usage limited(In fig 5, Usage default company-manager/Request default company-manager = 192/600 about equal to 33% in fig 4), keeping steady.
-
Before steady, auto-scaling may cause losing packages.
-
Company startup will cause temporarily increasing of the system resource load, so the CPU occupancy curve is showed like a crest-like, but HPA can accurately find the number of matching count of pods. In fig 3, count of pods has exceeded 3 which is actually required, and changed to 3 to keep the system steady.
-
The data of HPA and Granfana should be reported with some delay, official statement:
Starting and stopping pods may introduce noise to the metric (for instance, starting may temporarily increase CPU). So, after each action, the autoscaler should wait some time for reliable data. Scale-up can only happen if there was no rescaling within the last 3 minutes. Scale-down will wait for 5 minutes from the last rescaling. Moreover any scaling will only be made if:
avg(CurrentPodsConsumption) / Targetdrops below 0.9 or increases above 1.1 (10% tolerance).
It is all of the demonstrate above, anyway, Martin Fowler wrote in the March 2014 article:
“Microservices” - yet another new term on the crowded streets of software architecture. Although our natural inclination is to pass such things by with a contemptuous glance, this bit of terminology describes a style of software systems that we are finding more and more appealing. We’ve seen many projects use this style in the last few years, and results so far have been positive, so much so that for many of our colleagues this is becoming the default style for building enterprise applications. Sadly, however, there’s not much information that outlines what the microservice style is and how to do it.
Mr. Wang Lei, the forerunner of domestic practice micro-service, also held a comprehensive discussion in the book “Micro Service Architecture and Practice”.
Company based on ServiceComb, with micro-service properties, so we can doing fine-grained control to the single-load service Company-manager, to achieve the purpose of on-demand, this will greatly helpful to accurately and effectively solve the application bottlenecks, improve the efficiency of resource use.
Leave a Comment
Your email address will not be published. Required fields are marked *