Eventual Data Consistency Solution in ServiceComb - part 3
In my previous post, I talked about how Saga in ServiceComb is designed. However, there are quite a few data consistency solutions such as Two-Phase Commit (2PC) and Try-Confirm/Cancel (TCC). What makes saga special?
Two-Phase Commit (2PC)
Two-phase commit protocol is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit or abort (roll back) the transaction. 1
It has two phases:
- voting phase coordinator sends vote request to all services and services respond with either yes or no. If any service refuse with no or timeout, coordinator sends abort message in the next phase.
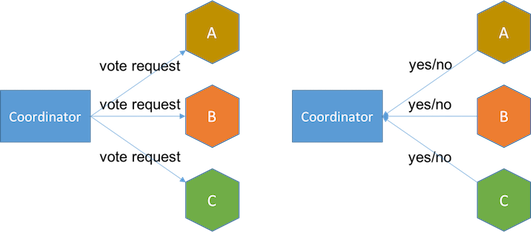
- decision phase if all services say yes, coordinator sends commit message to services and services acknowledge either transaction done or failed. If any service fails to commit, coordinator will initiate additional rounds to abort the transaction.
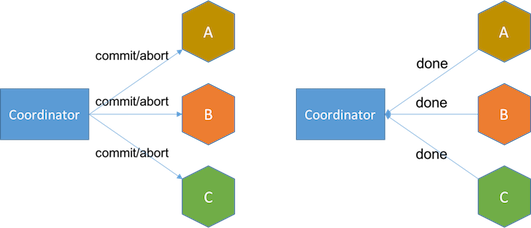
Between the end of voting phase and the end of decision phase, services are in uncertain state, because they are not sure if the transaction is going to proceed or not. When a service is in uncertain state and loses connection with coordinator, it may either wait for coordinator's recovery, or consult other services in certain state for coordinator's decision. In the worst case, n uncertain services broadcasting messages to other n - 1 services will incur O(n2) messages.
Another disadvantage of 2PC is that it is a blocking protocol. A service will block and lock resources, while waiting for decision from coordinator after voting. 2PC does not scale well when the number of services involved in a transaction grows, because of its blocking mechanism and worst case time complexity.
More details on implementation of 2PC can be found at 2 and 3.
Try-Confirm/Cancel (TCC)
TCC is a compensating transaction pattern for business model that is two-phased.
- try phase puts a service in pending state. For example, a try request in our flight booking service will reserve a seat for the customer and insert a customer reservation record with reserved state into database. If any service fails to make a reservation or times out, the coordinator will send a cancel request in the next phase.
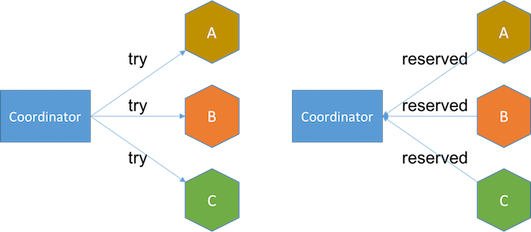
- confirm phase moves the service to confirmed state. A confirm request will confirm that a seat is booked for the customer and he or she will be billed. The customer reservation record in database will be updated to confirmed state. If any service fails to confirm or times out, the coordinator will either retry confirmation until success or involve manual intervention after it retries a certain number of times.
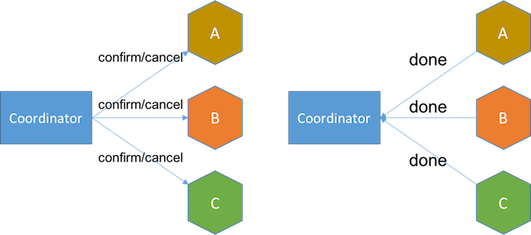
Comparing with saga, TCC has an advantage in that try phase transitions services into pending state instead of final state, which makes cancellation trivial to design.
For example, a try request for an email service may mark an email as ready to send and the email is only sent on confirm request. Its corresponding cancel request needs only to mark the email as obsolete. However, in case of using saga, a transaction will send the email and its corresponding compensating transaction may have to send another email to explain the problem.
The disadvantage of TCC, comparing with saga, is that its two-phased protocol requires services to be designed with additional pending state and interface to handle try request. And it may take twice the time to complete a TCC request than a saga request, because TCC communicates with each service twice and the confirm phase can only be started when responses of try request are received from all services.
More detailed explanation of TCC can be found at Transactions for the REST of Us.
Event Driven Architecture
In event driven architecture, just like TCC, an extra pending status is required for each service involved in a long live transaction. Services receiving transaction request insert a new record into its database with pending status and send a new event to the next service in the transaction sequence.
Because it's possible that a service crashes after inserting the record and we are not sure if the new event is sent, an extra event table is required for each service to keep track of which step the current long live transaction is in.
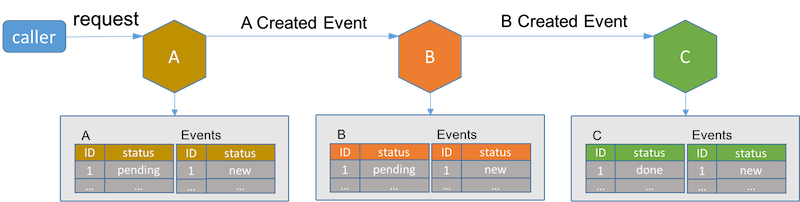
Once the last service in the long live transaction completes its job, it notifies the previous service in the transaction. Services receiving completion event set its record status to done in its database.
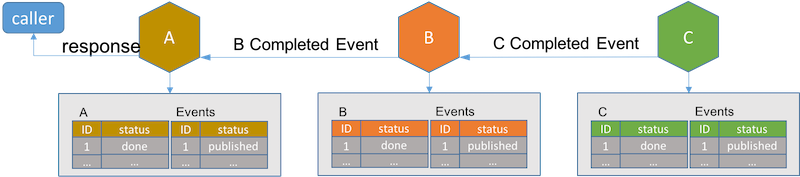
If you look closer, event driven architecture is just like a decentralized implementation of event driven TCC. If we remove the pending state for each service, this architecture looks like a decentralized and event driven saga. Being decentralized is good, but it creates much tighter coupling between services. Let's assume a new business requirement adds a new process D between B and C. With event driven architecture, service B and C have to change their code to accommodate the new process D.
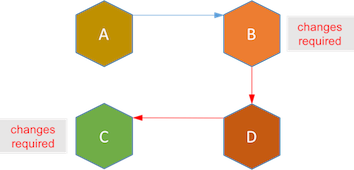
On the contrary, all these coupling is in saga and no change is required for existing services when a new process is added to the long live transaction.
More details can be found at Event-Driven Data Management for Microservices.
Centralized vs Decentralized
This blog series have been talked about centralized saga. But saga can be implemented as decentralized solution too. How does the decentralized version look like?
The decentralized version of saga does not have a dedicated coordinator. Whoever calling the next service in the transaction becomes the current coordinator instead. For example,
- service A receives a request requiring data consistency across service A, B, and C.
- A does its job and passes the request to the next service in the request, service B.
- B completes its part and passes the request to C, and so on.
- If C fails to process the request, it is B's responsibility to initiate its compensating transaction and asks A to rollback.

Comparing with centralized one, the decentralized version has the advantage of service autonomy. But each service is coupled with data consistency protocol, which may require additional persistence infrastructure.
We love services implementing business rules to be autonomous, but there are many application related complexity such as data consistency, service monitoring, and message passing, that are better to be centralized, so that business services are able to focus on dealing with business complexity instead of application complexity. That's why we designed centralized saga.
In addition, the relationship among services in a long live transaction becomes harder and harder to understand, as the number of services grows. It may quickly grow into a death star like the image below.
 Image source: http://www.slideshare.net/BruceWong3/the-case-for-chaos (s12)
Image source: http://www.slideshare.net/BruceWong3/the-case-for-chaos (s12)
Meanwhile, locating the root cause of a problem in a long live transaction also becomes more troublesome, since the service logs are spread all over cluster nodes.
Summary
In this article, we compared saga with other data consistency solutions. Saga is more scalable than two-phase commit and is preferable to TCC in scenarios where compensating transactions are feasible and minimal changes to business logic is required. Centralized saga decouples services from data consistency logic and its persistence infrastructure and allows easier troubleshooting of any problem occurred in transactions.
References
- https://en.wikipedia.org/wiki/Two-phase_commit_protocol
- https://cs.nyu.edu/courses/spring03/G22.2631-001/lecture8.pdf
- http://courses.cs.vt.edu/~cs5204/fall00/distributedDBMS/duckett/tpcp.html
- https://www.infoq.com/presentations/Transactions-HTTP-REST
- https://www.nginx.com/blog/event-driven-data-management-microservices/
Leave a Comment
Your email address will not be published. Required fields are marked *