ServiceComb中的数据最终一致性方案 - part 3
在我的前一篇文章,我谈到了ServiceComb下的Saga是怎么设计的。 然而,业界还有其他数据一致性解决方案,如两阶段提交(2PC)和Try-Confirm / Cancel(TCC)。那saga相比之下有什么特别?
两阶段提交 Two-Phase Commit (2PC)
两阶段提交协议是一种分布式算法,用于协调参与分布式原子事务的所有进程,以保证他们均完成提交或中止(回滚)事务。1
2PC包含两个阶段:
- 投票阶段 协调器向所有服务发起投票请求,服务回答yes或no。如果有任何服务回复no以拒绝或超时,协调器则在下一阶段发送中止消息。
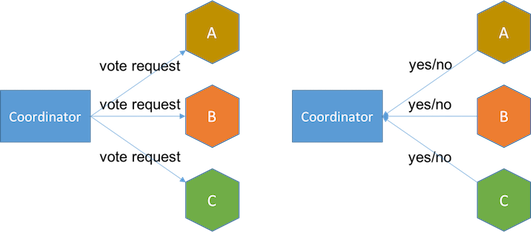
- 决定阶段 如果所有服务都回复yes,协调器则向服务发送commit消息,接着服务告知事务完成或失败。如果任何服务提交失败, 协调器将启动额外的步骤以中止该事务。
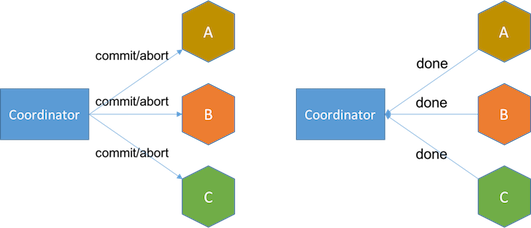
在投票阶段结束之后与决策阶段结束之前,服务处于不确定状态,因为他们不确定交易是否继续进行。当服务处于不确定状态并与协调器失去连接时, 它只能选择等待协调器的恢复,或者咨询其他在确定状态下的服务来得知协调器的决定。在最坏的情况下, n个处于不确定状态的服务向其他n-1个服务咨询将产生O(n2)个消息。
另外,2PC是一个阻塞协议。服务在投票后需要等待协调器的决定,此时服务会阻塞并锁定资源。由于其阻塞机制和最差时间复杂度高, 2PC不能适应随着事务涉及的服务数量增加而扩展的需要。
Try-Confirm/Cancel (TCC)
TCC也是补偿型事务模式,支持两阶段的商业模型。
- 尝试阶段 将服务置于待处理状态。例如,收到尝试请求时,航班预订服务将为客户预留一个座位,并在数据库插入客户预订记录,将记录设为预留状态。 如果任何服务失败或超时,协调器将在下一阶段发送取消请求。
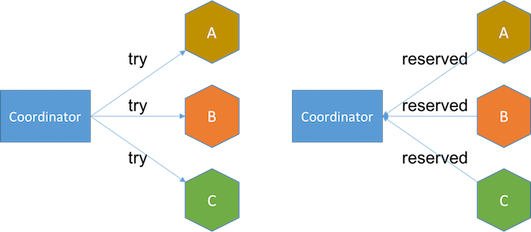
- 确认阶段 将服务设为确认状态。确认请求将确认客户预订的座位,这时服务已可向客户收取机票费用。数据库中的客户预订记录也会被更新为确认状态。 如果任何服务无法确认或超时,协调器将重试确认请求直到成功,或在重试了一定次数后采取回退措施,比如人工干预。
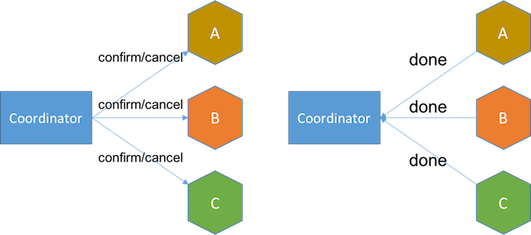
与saga相比,TCC的优势在于,尝试阶段将服务转为待处理状态而不是最终状态,这使得设计相应的取消操作轻而易举。
例如,电邮服务的尝试请求可将邮件标记为准备发送,并且仅在确认后发送邮件,其相应的取消请求只需将邮件标记为已废弃。但如果使用saga, 事务将发送电子邮件,及其相应的补偿事务可能需要发送另一封电子邮件作出解释。
TCC的缺点是其两阶段协议需要设计额外的服务待处理状态,以及额外的接口来处理尝试请求。另外,TCC处理事务请求所花费的时间可能是saga的两倍, 因为TCC需要与每个服务进行两次通信,并且其确认阶段只能在收到所有服务对尝试请求的响应后开始。
有关TCC的更多细节可参考Transactions for the REST of Us.
事件驱动的架构
和TCC一样,在事件驱动的架构中,长活事务涉及的每个服务都需要支持额外的待处理状态。接收到事务请求的服务会在其数据库中插入一条新的记录, 将该记录状态设为待处理并发送一个新的事件给事务序列中的下一个服务。
因为在插入记录后服务可能崩溃,我们无法确定是否新事件已发送,所以每个服务还需要额外的事件表来跟踪当前长活事务处于哪一步。
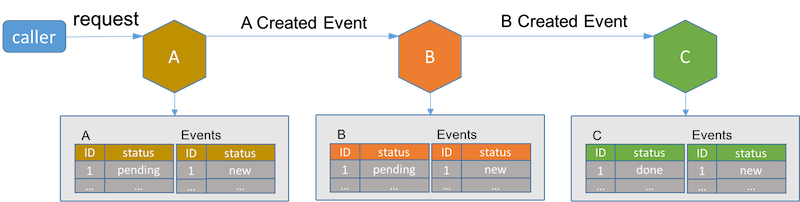
一旦长活事务中的最后一个服务完成其子事务,它将通知它在事务中的前一个服务。接收到完成事件的服务将其在数据库中的记录状态设为完成。
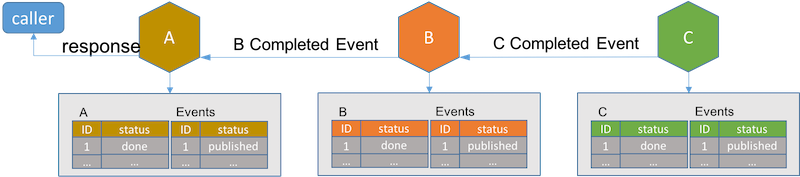
如果仔细比较,事件驱动的架构就像非集中式的基于事件的TCC实现。如果去掉待处理状态而直接把服务记录设为最终状态,这个架构就像非集中式的基于事件的saga实现。 去中心化能达到服务自治,但也造成了服务之间更紧密的的耦合。假设新的业务需求在服务B和C之间的增加了新的流程D。在事件驱动架构下,服务B和C必须改动代码以适应新的流程D。
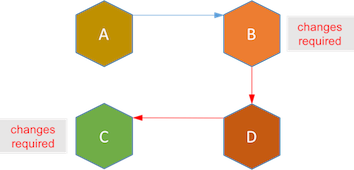
Saga则正好相反,所有这些耦合都在saga系统中,当在长活事务中添加新流程时,现有服务不需要任何改动。
更多细节可参考Event-Driven Data Management for Microservices.
集中式与非集中式实现
这个Saga系列的文章讨论的都是集中式的saga设计。但saga也可用非集中式的方案来实现。那么非集中式的版本有什么不同?
非集中式saga没有专职的协调器。启动下一个服务调用的服务就是当前的协调器。例如,
- 服务A收到要求服务A,B和C之间的数据一致性的事务请求。
- A完成其子事务,并将请求传递给事务中的下一个服务,服务B.
- B完成其子事务,并将请求传递给C,依此类推。
- 如果C处理请求失败,B有责任启动补偿事务,并要求A回滚。

与集中式相比,非集中式的实现具有服务自治的优势。但每个服务都需要包含数据一致性协议,并提供其所需的额外持久化设施。
我们更倾向于自治的业务服务,但服务还关联很多应用的复杂性,如数据一致性,服务监控和消息传递, 将这些棘手问题集中处理,能将业务服务从应用的复杂性中释放,专注于处理复杂的业务,因此我们采用了集中式的saga设计。
另外,随着长活事务中涉及的服务数量增长,服务之间的关系变得越来越难理解,很快便会呈现下图的死星形状。
 图片来源: http://www.slideshare.net/BruceWong3/the-case-for-chaos (s12)
图片来源: http://www.slideshare.net/BruceWong3/the-case-for-chaos (s12)
同时,在长活事务中定位问题也变得更加复杂,因为服务日志遍布群集节点。
Summary
本文将saga与其他数据一致性解决方案进行了比较。Saga比两阶段提交更易扩展。在事务可补偿的情况下, 相比TCC,saga对业务逻辑几乎没有改动的需要,而且性能更高。集中式的saga设计解耦了服务与数据一致性逻辑及其持久化设施, 并使排查事务中的问题更容易。
References
- https://en.wikipedia.org/wiki/Two-phase_commit_protocol
- https://cs.nyu.edu/courses/spring03/G22.2631-001/lecture8.pdf
- http://courses.cs.vt.edu/~cs5204/fall00/distributedDBMS/duckett/tpcp.html
- https://www.infoq.com/presentations/Transactions-HTTP-REST
- https://www.nginx.com/blog/event-driven-data-management-microservices/
留下评论
您的电子邮箱地址并不会被展示。请填写标记为必须的字段。 *